

Un modo chiave di differenziare le notizie a valore aggiunto da quelle di contenuto commerciale è di rimodulare il concetto di link.
Grazie alla semantica e alle API (Application Programming Interfaces), potremmo passare da collegamenti per così dire scioccamente improduttivi, a collegamenti che producono sapere.
Questo in sintesi l’indicazione che Frédéric Filloux illustra in un ampio articolo su Mondaynote, di cui presentiamo qui la traduzione.
#eJournalism è una rubrica settimanale promossa da Key4biz e LSDI (Libertà di stampa, diritto all’informazione).
Per consultare gli articoli precedenti, clicca qui.
How Linking to Knowledge Could Boost News Media
Molte testate giornalistiche sono ancora bloccate alla versione 1.0 del link, e non lo usano come risorsa: quando producono contenuti appongono tag ed aggiungono collegamenti per lo più interni, che, al massimo, rimandano ad altri contenuti, sempre interni; questo avviene a causa della paura che il lettore possa sfuggire, se viene aperta una porta troppo vasta…
Assegnare i tag non è una scienza esatta: ho notato di recente che un articolo su una nuova gravidanza nella famiglia reale britannica era stata taggata come “Demografia”, nemmanco fosse un trattato sulla fiacchezza della fertilità teutonica….
I modi attuali di impaginare e strutturare gli argomenti sono un mero primo passo: sono degli strumenti compulsivi, obbligatori per arpionare il lettore entro il perimetro della pubblicazione; l’intero meccanismo sta migliorando, però. Qualche pubblicazione usa di già il profilo dati del lettore per assegnargli dinamicamente, modulatamente storie a lui correlate e basate su sue presunte affinità. Un ipotetico lettore che stia immerso in un pezzo su General Electrics potrebbe notare delle differenze nell’insieme degli articoli che gli vengono sottoposti se il suo profilo raccontasse di lui come di un professionista nell’ambito legale, finanziario o piuttosto ingegneristico.
Ma siamo solo agli albori, in questo campo: due fattori sono all’opera, in quest’ambito… Le API (ovvero Application Programming Interfaces) agiscono come il recettore sinaptico di una cellula che scambia, come avviene nel corpo umano, segnali chimici guida con le altre cellule: è il modo migliore di connettere un’ampia varietà di contenuti con il mondo esterno; un video, un articolo, una grafica può così “parlare a/essere letto da” varie pubblicazioni, archivi dati ed altri “organismi”. Ma esso deve prima passare attraverso filtri semantici: da un testo, i filtri più elementari estrapolano insiemi di parole ed espressioni quali entità nominali, patronimici, luoghi.
Un ulteriore livello, più elevato, coinvolge ed estrae significati come “X acquisisce Y per Z milioni di dollari”, oppure “Alfa è stato nominato Primo Ministro …” ecc.
E cosa ne è di un video?
Alcuni sistemi godono di sistemi di tagging granulare; altri, come Ted Talks, sono dotati di sistemi di trascrizione multilingue, la qual cosa fornisce preziosa materia prima grezza, di valore per l’analisi semantica. Ma la maggior parte dei contenuti rimane bloccata in forma muta e molto spesso taggata in forme non strutturate: questo richiede complessi trattamenti affinché siano resi leggibili dal mondo esterno.
Per esempio, un video non trascritto individuato come interessante (diciamo una intervista a Charlie Rose), dovrà esser sottoposta ad una analisi e ad un procedimento “da-discorso-a-testo”, per divenire utilizzabile; questi procedimenti richiedono sia opera umana (scoprire quali contenuti valgano la pena di esser sottoposti al procedimento), sia l’uso di sofisticata tecnologia (la trascrizione di un discorso pronunciato da qualcuno che parli molto velocemente o con fortissimo accento).
Una volta risolti problemi come questi, un intero mondo completamente nuovo e gravido di conoscenza emerge: si entra nella “Semantic Culturonomics” (economia della semantica culturale, ndr). Il termine è stato coniato da due ricercatori che lavorano in Francia, Fabian Suchanek and Nicoleta Preda.
Ecco un breve stralcio del loro saggio (Grazie a Christope Tricot per lo spunto).
I quotidiani sono testimonianze della storia. Lo stesso è vero, in maniera crescente, per le piattaforme sociali, quali i forum in Rete, le comunità web, i blog etc.
Semantic Culturonomics
La Semantic Culturonomics è un paradigma che usa le basi della conoscenza semantica al fine di dare significato ai corpi testuali, che siano notizie o derivati da piattaforme sociali web. Questa idea non è priva di sfide interessanti, perché necessita di un collegamento tra un corpo testuale ed un sapere stravagante, fuor del comune, così come l’abilità di scavare un modello dati ibrido che tratti andamenti tendenziali e regole logiche. La semantica trasforma il testo in una ricca e profonda fonte e risorsa di conoscenza, mostrando sfumature che i metodi di analisi odierni stentano ancora, ciechi, a dimostrare. Questo potrebbe dimostrarsi di grande utilità, e non solo per storici e studiosi di linguistica, ma anche per giornalisti, sociologi, opinionisti e politologi…
In altre parole, guardato attraverso le mie lenti, questi due scienziati suggeriscono di andare da questo:
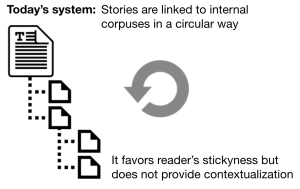
A questo:
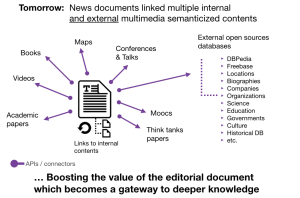
Ora, immaginate questo: una ipotetico servizio su un argomento importante, il pensiero di General Electric sul cambiamento climatico, pubblicato sul Wall Street Journal, sul Financial Times o sull’Atlantic, che si apre improvvisamente ad una vasta rete di conoscenze: il testo (insieme a grafica, video, etc) fornito da uno staff giornalistico, viene amplificato dalla possibilità di accesso a tre libri che trattano di riscaldamento globale, da due Ted Talks, da molteplici archivi di dati contenenti riferimenti a luoghi e persone menzionate nella storia, un trattato accademico di Knowledge@Wharton, un MOOC (massive open online courses, ovvero corsi di varia natura aperti a tutti ed in Rete, ndr) di Coursera, un sondaggio realizzato da un istituto scandinavo di ricerca, un documentario del National Geographic, ecc.
Dal momento che, presumibilmente, tutto questo materiale è semanticamente riconducibile e viene espresso nella stessa ”lingua franca” in cui il contenuto giornalistico originale è scritto, il processo è largamente automatizzato.
Grande! Ma… dov’ è il valore, per le testate giornalistiche, direte voi?
Innanzi tutto, una pubblicazione affidabile (ed un sottotitolo che lo sia altrettanto), che offra un prodotto così tanto curato ai propri lettori, è molto più probabile che possa attrarre un pubblico pagante: i lettori saranno invogliati a pagare per un prodotto, un servizio che nessun altro offre. Inoltre, si può guadagnare con la business-to-business intelligence attraverso una sapiente etichettatura (tagging) e la capacità di strutturare e inserire link. Dei prodotti di tanto pregio potrebbero apporterebbero un enorme valore perché sarebbero unici, innovativi, basati sulla fidelizzazione, sulla selezione e sulla pertinenza.
(Traduzione a cura di Maria Daniela Barbieri)

