Italia


Pubblichiamo il secondo dei due saggi sul web semantico, scritto da Ignazio Licata, Luigi Lella, William Giordano. Un ringraziamento particolare degli autori va a Emanuele Somma, Michele Monti e Matteo Giacomazzi di Infomedia e a “Computer Programming”.
***
I modelli di rappresentazione della conoscenza ispirati all’attività della mente umana stanno avendo un impatto decisivo sulla progettazione di nuove interfacce uomo-macchina, e rendono possibile l’idea del web come global brain,una rete associativa dinamica capace di operazioni di information retrieval centrate sull’utente.
1. Introduzione
Quando negli anni ’50 i primi computer fecero la loro apparizione in società, uscendo dai laboratori, ed iniziando il loro cammino nell’attività produttiva di istituzioni e aziende, cominciò ad essere usato dai media il termine “cervello elettronico”, che colpì subito l’immaginario collettivo e tanta parte giocò nella mitologia della prima intelligenza artificiale. Dovranno passare almeno 30 anni, ed un consistente sviluppo delle scienze cognitive, per comprendere in profondità i limiti dell’intelligenza dell’onnipresente dispositivo con il quale ci confrontiamo tutti i giorni!
Del resto un singolo neurone, nonostante tutta la sua intensa attività computazionale, non può certo dirsi “intelligente” (qualunque cosa si voglia intendere in prima approssimazione con questo termine notoriamente insidioso…), e dunque ci si può chiedere cosa può accadere se colleghiamo un alto numero di computer assieme in una vasta rete, che viene a rappresentare così la forma più evoluta di quell’intelligenza collettiva costituita dallo scambio di informazioni tra singoli e gruppi attraverso un gran numero di tecnologie, e potrebbe essere paragonata dunque alle parti più “moderne” del nostro cervello, come la corteccia cerebrale.
L’idea della rete come “global brain” nacque come metafora agli inizi degli anni ’90, per diventare in tempi più recenti un soggetto di studio piuttosto sofisticato con l’avvento del world wide web, i cui comportamenti sono estremamente complessi e chiamano in gioco un gran numero di competenze per sviluppare la rete, rendere più efficiente la ricerca e lo scambio di informazioni e difenderla da attacchi e crisi di varia natura. Al momento si può dire che l’idea del www come una sorta di corteccia cerebrale del pianeta è qualcosa di più di una semplice metafora, visto che è possibile formulare dei modelli matematici basati su forti analogie con strutture bio-morfe, e molto meno una forma “autentica” di intelligenza. Quello che possiamo dire con certezza è che la conoscenza della complessità delle rete, ed in particolare gli aspetti caratteristici di “memoria associativa” ci permettono oggi di progettare nuovi modelli dell’interazione uomo-macchina sempre più efficienti, e capaci di seguire le direttive “semantiche” dell’utente.
2. La rappresentazione della conoscenza
Nello studio dei sistemi cognitivi naturali o artificiali, il problema della rappresentazione della conoscenza occupa un ruolo centrale. Da come questa viene rappresentata dipende infatti la struttura e la performance del sistema. La ricerca in questi campi si pone l’obiettivo di realizzare dispositivi efficaci per il recupero delle informazioni in modo “contestualizzato”, ossia in grado di effettuare l’analisi dei documenti in relazione al dominio semantico dell’utente. Inoltre, Internet pone anche il problema dell’interazione tra agenti intelligenti con competenze e finalità molto diverse. E’ necessario dunque che la conoscenza possa essere messa in forma tale da poter essere “negoziata” facilmente tra domini semantici assai differenti.
Storicamente sono stati utilizzati principalmente cinque tipi di sistemi per la rappresentazione della conoscenza. Il più semplice e noto è costituito dal database, un insieme di caselle ognuna delle quali contiene una certa quantità di informazione. Questo insieme può essere strutturato mediante l’uso di puntatori, che permettono di connettere in modo articolato il contenuto di più caselle.In genere, i database sono ottimi strumenti per applicazioni piuttosto semplici e in contesti molto limitati.
I feature systems utilizzano invece gli strumenti della logica formale, e sono stati sviluppati nell’ambito della filosofia, della linguistica e della psicologia cognitiva. L’obiettivo originale di questa forma di rappresentazione è quello di trovare un insieme finito di caratteristiche semantiche di base (features) definite senza ambiguità che, combinate attraverso determinate regole di composizione, permettano di esprimere concetti più complessi. Questo tipo di sistemi sono in genere adatti a trattare situazioni in cui le regole di composizione possono “coprire” l’intero ambito della conoscenza a partire dai features di partenza.Questo sfortunatamente è un caso piuttosto raro. Inoltre il procedimento è “insensibile” al cambiamento di contesto e di obiettivi. Le reti associative hanno il pregio di considerare anche le relazioni semantiche in modo esplicito. Sono la più antica forma di rappresentazione della conoscenza, e può essere fatta risalire ad Aristotele. Nelle reti associative la conoscenza è rappresentata come una rete di concetti legati da associazioni più o meno forti. L’aspetto grafico delle reti semantiche è quello di nodi variamente connessi tramite archi che indicano la relazione semantica tra due concetti. Tale formalismo è avvalorato da una estesa varietà di dati sperimentali come ad esempio gli esperimenti di word priming, ma è chiaro che non tutta la conoscenza può essere rappresentata in questo modo. Bisogna infatti tener conto della possibilità che una relazione sia ambigua, o si modifichi in strutture diverse a seconda dell’obiettivo perseguito.
Le reti semantiche costituiscono un’evoluzione delle reti associative. In questo caso i concetti sono identificati con dei nodi, ma questi sono collegati da archi etichettati (IS-A, PART-OF etc.). In questo modo è possibile definire delle gerarchie di concetti ben ordinate, ed è permessa l’ereditarietà delle proprietà.
Gli schemi, come i frames e gli scripts ,sono strutture utilizzate per coordinare concetti facenti parte di una stessa superstruttura che identifica un dominio semantico in qualche modo unitario. Esempi classici sono dati dal room-frame di Minsky e dallo script del ristorante di Schank e Abelson. Nel primo caso tutti i termini che possono essere correlati alla nozione di “stanza” , come porta, finestra, letto, etc. giocano il ruolo di “attributi” in uno stesso frame, mentre uno script memorizza una serie di eventi-tipo legati ad una situazione, come in una piccola sceneggiatura.
Il problema di tutte queste forme di rappresentazione, come abbiamo visto, è costituito dalla loro staticità, che limita fortemente il gioco dinamico dei significati.E’ necessario dunque ricorrere ad una forma di rappresentazione della conoscenza in grado di aggiornarsi continuamente, generando nuove strutture, e ridefinendo il dominio semantico durante il processo di ricerca.
3. Knowledge Nets e Long Term Memory
Le reti cognitive (knowledge nets) sono un formalismo alternativo introdotto nello studio dei processi cognitivi da W.Kintsch che combina ed estende gli aspetti vantaggiosi di tutti i sistemi di rappresentazione citati. Queste, infatti, sono disorganizzate e caotiche, ma la loro struttura cambia dinamicamente nel tempo sulla base dell’esperienza accumulata e la struttura conoscenza può essere così organizzata tramite procedure particolari che tengono conto del contesto globale e della sua modificazione dinamica in relazione alle sequenze di input di attivazione, e più in generale alle esigenze dell’utente.
Le caratteristiche generali della teoria sono piuttosto semplici. Anche in questo caso lo schema predicato-argomento può essere considerato come l’unità linguistica fondamentale, specie nella rappresentazione del contenuto dei testi. Le proposizioni atomiche consistono di un termine relazionale (il predicato) e da uno o più argomenti.Le reti cognitive collegano tali proposizioni atomiche tramite degli archi non etichettati e pesati.In questo modo il significato di un nodo è dato dalla sua posizione nella rete, e dal suo peso variabile. Solo quei nodi che sono attivi, e che definiscono la memoria di lavoro (WM,working memory), contribuiscono a specificare il significato di un nodo. I concetti quindi non hanno un significato permanente e fisso, ma questo viene di volta in volta costruito nella memoria di lavoro attivando un certo sottoinsieme delle proposizioni nell’intorno del nodo che rappresenta il concetto. Il contesto di utilizzo (gli obiettivi, l’esperienza accumulata, lo stato emotivo e situazionale etc.) determina quali nodi debbano essere attivati.
Un passo successivo consiste nel definire le modalità di recupero delle informazioni.Con K.A. Ericsson ,V.L.Patel, W. Kintsch ha introdotto il concetto di memoria di lavoro a lungo termine (LTWM, Long Term Working Memory). Questa nozione è resa necessaria dalla difficoltà di spiegare diversi compiti cognitivi, quali la comprensione di un testo, utilizzando soltanto il concetto di memoria di lavoro. Dati i severi limiti di capacità della memoria a breve termine (STM, Short Term Memory) e della memoria di lavoro (WM) non si riusciva a capire infatti come potessero essere svolti dei compiti che richiedessero un enorme utilizzo di conoscenze generali. Appariva perciò necessario introdurre un nuovo modulo in grado di connettere il ristretto dominio della memoria di lavoro con il più ampio bacino di risorse cognitive dell’agente intelligente.
La teoria della memoria di lavoro a lungo termine specifica sotto quali condizioni la capacità della WM possa essere estesa. La LTWM è coinvolta solo nell’esecuzione di compiti e azioni ben conosciuti, inquadrabili cioè in particolari domini cognitivi su cui è già stata maturata molta esperienza. La memoria di lavoro in questi casi è quindi suddivisibile in una parte a breve termine (STWM) avente capacità limitata e nella LTWM che è un sottoinsieme della memoria a lungo termine,rappresentabile attraverso una rete di proposizioni, che viene richiamata durante l’attività. Il contenuto della STWM rappresenta dunque una sorta di seme informazionale che genera la LTWM. Precisamente gli oggetti presenti nella STWM attivano altri oggetti presenti nella LTM tramite strutture di memoria fisse e stabili (retrieval cues), definite tramite l’esperienza. In questo modo ogni compito cognitivo è svolto non soltanto sulle questioni specifiche “urgenti” e “primarie”, presenti nella memoria di lavoro a breve termine, ma utilizzando anche una più vasta contestualizzazione residente nella LTWM.
4. Implementazione del modello di Kintsch-Ericsson-Patel
Se si adotta il formalismo della rete di proposizioni per la rappresentazione della conoscenza sorgono due grossi problemi implementativi. Il primo è relativo al processo di creazione della LTWM. Il secondo è invece relativo al problema dell’attivazione dei nodi della LTM, cioè alla formazione dei retrieval cues. Bisogna infatti tenere presente che in un modello cognitivo realistico non è possibile stimare a priori un numero ideale di nodi recuperabili dallo spazio semantico per ogni parola presente nella STWM. Inoltre la posizione occupata da una parola all’interno della LTWM ,in termini di relazioni con le altre parole ivi presenti, è determinata dall’esperienza, ovvero dall’uso continuato che viene fatto di quella parola. A rigore Kintsch parla di lifetime experience. In una prima fase lo stesso Kintsch ha suggerito l’uso di un dizionario come WordNet nella definizione dello spazio semantico da cui si ricava la LTWM. Questo procedimento appare piuttosto limitante, e del resto studi successivi hanno mostrato poi come non porti sempre alla disambiguazione semantica desiderata della frase analizzata. L’ideale sarebbe dunque di abbandonare la rappresentazione intermedia dello spazio semantico e sviluppare dei metodi che portino alla formazione diretta di reti associative di concetti o di proposizioni, in modo da far sì che dal contenuto della STWM emerga in modo naturale l’attivazione della LTWM, dove il termine emergenza è usato nello stesso senso della fisica dei sistemi complessi.
Presentiamo ora nelle sue linee essenziali il sistema per l’acquisizione della conoscenza che abbiamo sviluppato sulla base del modello originale della LTWM di Kintsch-Ericsson sulla base di suggestioni che derivano dalla fisica dei sistemi auto-organizzanti. La mancanza di parser testuali adeguati, in grado cioè di convertire i paragrafi di un testo nelle proposizioni atomiche equivalenti, ci ha spinto a sviluppare, almeno nella fase iniziale del progetto, dei semplici modelli dinamici di reti associative che hanno il vantaggio di poter essere facilmente studiate attraverso semplici modelli statistici.
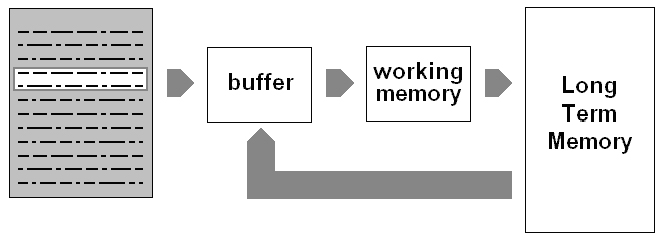
(Figura 1 – Possibile architettura di un sistema per l’acquisizione dinamica della conoscenza da un archivio di dati in formato elettronico).
La parte del contenuto del documento che si sta analizzando, presente nel buffer, deve essere opportunamente codificata tenendo conto del contesto in cui è collocata prima di essere elaborata dal blocco che implementa la memoria di lavoro. Il contesto rappresenta l’argomento trattato dalla parte del contenuto elaborato e per individuarlo correttamente occorre considerare non solo l’informazione che è stata già analizzata nel documento, ma anche quella che è possibile richiamare dalla struttura che rappresenta la conoscenza accumulata nel corso delle varie analisi effettuate in precedenza, e che risiede nella Long Term Memory.
Per implementare il blocco della memoria di lavoro si possono utilizzare reti neurali auto organizzanti assieme a procedure di labeling dei nodi da utilizzare dopo il loro addestramento, ma questo comporta tempi computazionali eccessivamente elevati, soprattutto se si vogliono elaborare interi archivi di documenti testuali. Per arrivare alla definizione di una rete associativa abbiamo quindi preso in considerazione altri modelli, basati sulla teoria dei grafi scale-free.Questi modelli sono ben noti in fisica statistica, ed hanno un significato assolutamente generale che riguarda la capacità del sistema di amplificare la propria informazione attraverso processi di auto-organizzazione. Studi recenti indicano che la conoscenza accumulata dagli esseri umani sembra essere strutturata come un grafo scale-free . Se si rappresentano con dei nodi parole o concetti, alcuni di questi (hub, in inglese, letteralmente “mozzo di ruota”) sembrano stabilire molti più collegamenti rispetto agli altri nodi. Questa particolare conformazione sembra ottimizzare la comunicazione tra i nodi visto che proprio grazie alla presenza degli hub ogni coppia di nodi può essere unita attraverso un basso numero di collegamenti; dunque la definizione e l’eventuale aggiornamento di un modello di rete scale-free non richiede molto tempo; inoltre l’esecuzione di processi quali la diffusione dell’attivazione all’interno di tali strutture risulta molto veloce.
Nel dettaglio la tecnica di analisi testuale sviluppata procede nel seguente modo:
A) Il testo viene analizzato paragrafo per paragrafo;
B) Il Buffer deve contenere non solo le parole presenti nel paragrafo analizzato, ma anche le parole richiamate dalla Long Term Memory attraverso la procedura di diffusione dell’attivazione che parte dai nodi della LTM che rappresentano le parole presenti nel Buffer. Il Buffer, la Working Memory e la parte della LTM che viene attivata possono essere paragonate alla LTWM di Kintsch-Ericsson;
C) Durante l’acquisizione del contenuto del paragrafo si utilizza una stoplist di parole da non considerare (come articoli, pronomi, etc.);
D) Per ogni parola presente nel testo vengono memorizzati i paragrafi in cui questa compare,o in cui è stata richiamata. Una volta effettuato il parsing di tutto il testo e memorizzati i dati di tutte le N parole incontrate può iniziare la formazione della rete associativa nella memoria di lavoro;
E) Si parte con una rete composta da N nodi non collegati. Ad ogni passo t=1..N ognuna di queste unità ,associata ad una delle N parole, stabilisce un collegamento con altre M unità. Sia j l’unità selezionata.
La probabilità che l’unità j stabilisca un collegamento con l’unità i-esima è data da: Pi=Ui*Ki/(U1*K1+…+UN*KN)
dove Ki è il grado (numero di collegamenti) della i-esima unità, mentre Ui è la funzione di utilità (fitness) della i-esima unità definita nel seguente modo : Ui=(n.paragrafi in cui compaiono i E j)/(n.paragrafi in cui compaiono i OPPURE j).
E’ importante notare che nel nostro modello la funzione di fitness non si riferisce mai ad un singolo nodo, ma sempre ad una coppia. Questa scelta permette di valutare il ruolo degli hub nel gioco variabile delle connessioni tra unità anche molto distanti tra loro.
La LTM è un’altra rete associativa, con la differenza che i collegamenti sono pesati.Questa condizione corrisponde alla naturale “sedimentazione” della conoscenza acquisita da tempo.
Ogni volta che un collegamento della Working Memory -cioè della rete associativa relativa al nuovo documento analizzato- corrisponde ad uno già presente nella LTM, il peso di quest’ultimo viene aumentato di 1.
Esempio :
La WM collega “Hemingway” a “writer”.
Nella LTM “Hemingway” è collegato a “writer” con peso 7 e a “story” con peso 4.
Nella LTM aggiornata “Hemingway” sarà collegato a “writer” con peso 8 e a “story” con peso 4 (invariato).
Nella procedura della diffusione dell’attivazione questi pesi vanno normalizzati. “Hemingway” va cioè collegato a “writer” con peso 8/(8+4) e a “story” con peso 4/(8+4).
Quello che si osserva durante questa procedura ha un andamento caratteristico che costituisce la chiave fondamentale della “fisica del web”.
5. La Fisica del WEB:Small-worlds e analogie con i sistemi complessi
Dimentichiamoci per un attimo della rete come prodotto ingegneristico, fatta di macchine assai eterogenee tra loro, protocolli, routers , connessioni e server, e pensiamola come un sistema di tipo fisico-matematico, dove si manifestano comportamenti collettivi di vario tipo. Da un punto di vista matematico una rete può essere descritta da un grafo. La teoria dei grafi è un magnifico esempio di matematica “pura”, semplice nei suoi principi fondamentali, che si è sviluppata in modo largamente indipendente dalle numerose possibilità applicative che oggi si stanno vagliando: reti metaboliche, proteine, analisi dei gruppi sociali, ecosistemi, etc. E’ doveroso ricordare qui almeno Paul Erdős (1913-1996), geniale matematico ungherese che ha dato contributi fondamentali alla teoria. Per i nostri scopi sarà utile qui considerare un grafo che si sviluppa in modo incrementale secondo una regola molto semplice legata alla probabilità di connessione tra due nodi, uno vecchio ed uno nuovo. Questa probabilità sarà tanto più alta quanto più il vecchio nodo ha un alto numero di vertici (quanto più è cliccato).In questo caso è possibile dimostrare che l’intera rete ha una configurazione retta da una legge di potenza del tipo ![]()

Naturalmente una rete è un’entità dinamica. Nel caso del web ogni giorno si aggiungono nuove pagine, ed altre invece scompaiono. Per descrivere questo processo è utile introdurre una funzione di fitness che misura come si modifica la connettività con l’aggiunta o la scomparsa di nuovi nodi. L’analisi mostra un fenomeno interessante. Le reti small-world sono estremamente flessibili e robuste; l’aggiunta o la rimozione di gran parte dei nodi non modifica in modo drastico la struttura globale, tranne quando viene colpito un nodo “cruciale”. Utilizzando strumenti statistici utilizzati in teoria quantistica dei campi, in una pubblicazione ormai celebre, Ginestra Bianconi e Laszlo Barabasi hanno dato un’interessante spiegazione fisica del comportamento delle reti scale-free. Interpretando la funzione di fitness come una sorta di “temperatura” della rete,legata all’attività dinamica di comparsa e scomparsa dei nodi, si mostra che al di sotto di certi valori critici del parametro b della legge di potenza si hanno delle forme di “cristallizzazione” dei vertici “bosoni” in alcuni nodi particolari, che vengono a svolgere il ruolo dei livelli energetici (condensazione di Bose-Einstein). In altre parole è possibile dire che la conoscenza contenuta nella rete tende ad autoorganizzarsi sulla base di un gruppo di nodi super-connessi che emergono naturalmente dall’attività del web.
A questo punto si pongono alcune domande interessanti sulla struttura globale della rete. E’ possibile indurre delle “statistiche” alternative, guidare la rete verso forme organizzative diverse ? Sarebbe vantaggioso? A tal proposito è interessante un’osservazione del fisico Ricard Solè, che ha mostrato come strutture tipo small-world hanno un evidente vantaggio evolutivo che troviamo anche in natura o in altri ambiti, come nei legami proteici o nell’ organizzazione del linguaggio, studiata da Solè con Ramon Ferrer i Cancho. Le “reti di piccolo mondo”, dato il forte valore di clustering, vengono ad avere una sorta di struttura “modulare” che ne favorisce la sopravvivenza nei casi in cui interi pezzi vengano danneggiati. Sembra dunque che anche l’informazione condivisa dall’intelligenza distribuita in rete tenda a riprodurre un efficace modello naturale basato sul principio “tutti sono utili e quasi nessuno è indispensabile”. Utilizzando una LTM è possibile, in un certo senso, attivare una ricerca mirata agli obiettivi dell’agente umano, definendo un “piccolo mondo” che si riconfigura sulle domande dell’utente. La struttura è sempre di tipo scale-free, ma è come se l’intero mondo della conoscenza “collassasse” intorno alla domanda del ricercatore che interroga la rete. L’aggiornamento della LTM avviene attraverso un’integrazione continua, correlata ai vari passi della ricerca. In questo modo si ottiene la possibilità di “proiettare” sulla struttura dell’intera rete il gioco di connessioni significative che costituisce l’obiettivo dell’utente e che risiede nella LTM, che viene ad essere così un deposito modulare dinamico di risorse in progress. Un punto interessante è che l’uso di semplici strumenti statistici permette di seguire e valutare il funzionamento dell’intero processo. E’ possibile dimostrare che l’attività della LTM dinamica così definita funziona come un amplificatore di informazione. Ad ogni passo della ricerca si opera una destrutturazione delle connessioni esistenti (dissipazione) per poterne costruire di nuove. Questo equivale ad un fenomeno di emergenza intrinseca, in cui compaiono continuamente nuovi “codici” che guidano il recupero e l’elaborazione di informazione. Le simulazioni hanno ampiamente confermato questa teoria.
6. Valutazione del Modello di WM sviluppato
Per testare la validità del modello di rete scale-free adottato per la WM sono state effettuate delle prove di analisi disabilitando la procedura di recupero dell’informazione dalla LTM.
Sono stati presentati consecutivamente al sistema 100 files del Reuters Corpus, ottenendo delle reti associative (WM) caratterizzate dalla tipica struttura dei grafi scale-free.
Sono state testate due versioni del modello, una con i collegamenti bidirezionali e un’altra con i collegamenti diretti (in questo caso nel calcolo della probabilità della creazione del collegamento si è considerato Ki=Ki(IN)+Ki(OUT)).
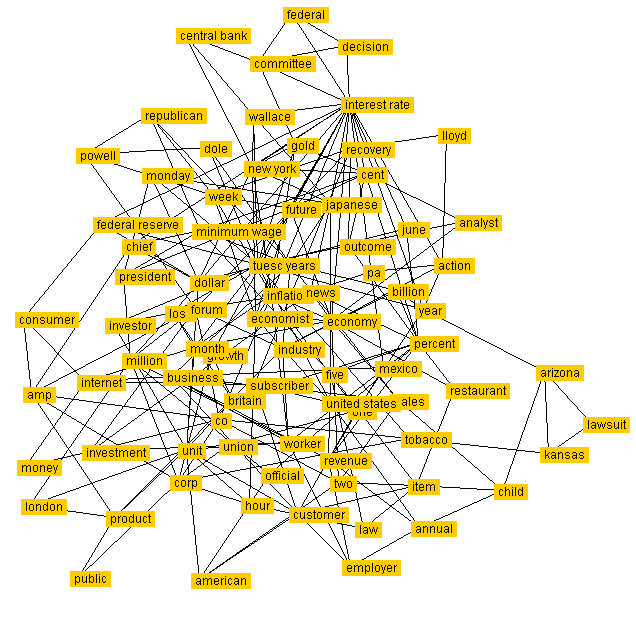
Nella fig.2 è rappresentato un esempio di rete associativa con collegamenti bidirezionali. Il carattere prettamente economico degli articoli presentati giustifica la presenta di hub quali interest rate, economy, percent etc.
(Figura 2 – rete con collegamenti bidirezionali relativa al contenuto testuale di 100 files del Reuters Corpus).
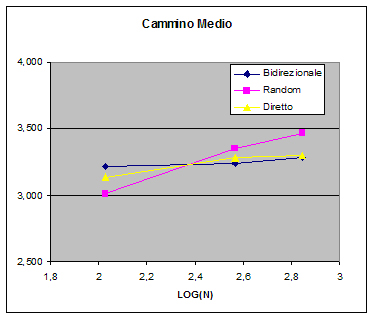
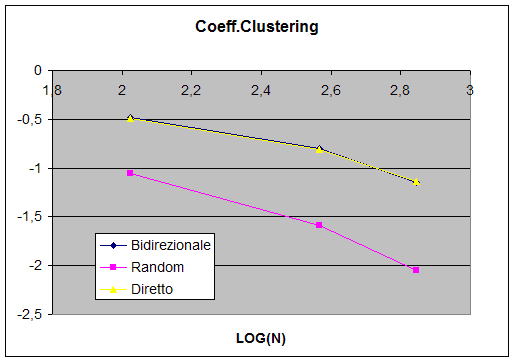
Consulta i grafici relativi al cammino medio (fig.3 e fig.4), al coefficiente di aggregazione (fig.5 e fig.6) e alla funzione di distribuzione dei gradi dei nodi relativi ai grafi ottenuti (fig.7, fig.8 e fig.9,fig.10).
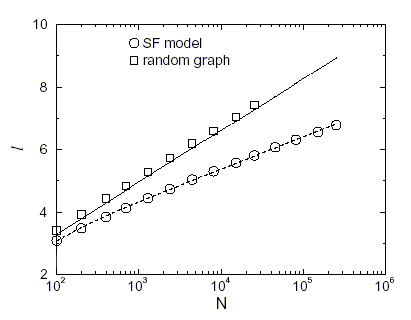
Nonostante i pochi punti riportati, la tendenza del cammino medio risulta essere abbastanza chiara. La pendenza del grafo random è molto diversa da quelle degli altri due. Tale risultato conferma quello ottenuto da Barabási riportato nel Grafico 4 (Cammino medio di un grafo scale-free con ![]()

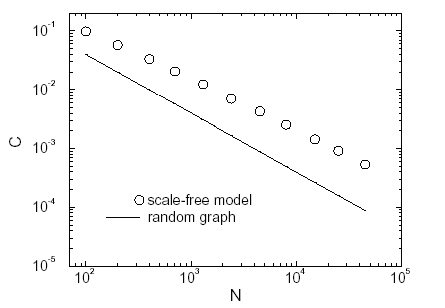
Nel Grafico 5 (Coefficienti di clustering a confronto) è da notare non solo la dipendenza inversa rispetto ad N, ma soprattutto il fatto che il parametro della rete associativa realizzata è almeno un ordine di grandezza superiore a quello del grafo casuale, chiaro indice di una forma di auto-organizzazione del sistema. Anche questo risultato è in sintonia con quelli ottenuti da Barabási che possiamo osservare nel Grafico 6 (Coefficiente di clustering di un grafo scale free con e di un grafico random con stessa grandezza e grado medio – risultati di Barabasi – ).
![]()

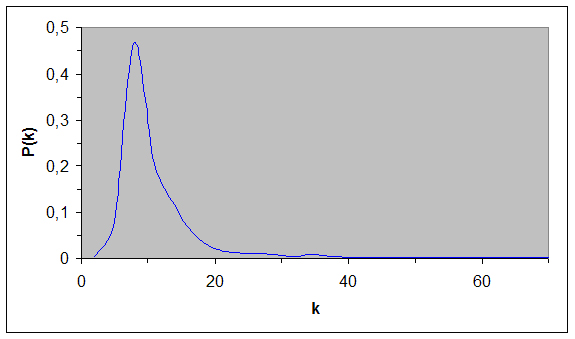
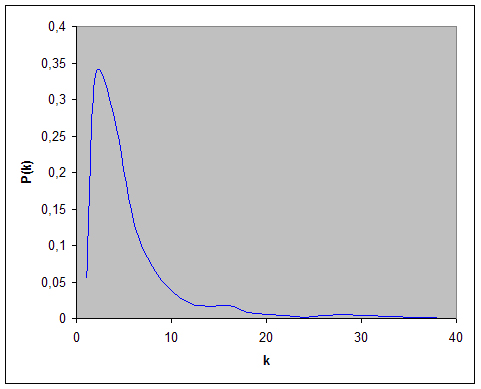
Prendiamo ora in considerazione il parametro fondamentale delle reti Scale Free: la funzione di distribuzione dei gradi ![]()

Nel Grafico 7 (funzione di distribuzione dei gradi per una WM con N=699, M=5 e collegamenti bidirezionali) è riportata la curva ![]()

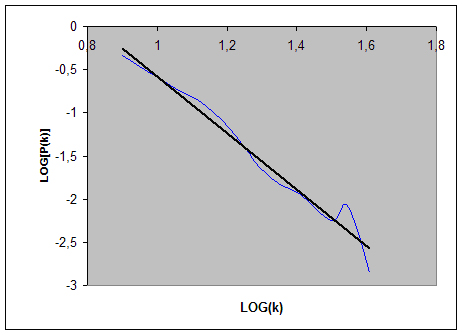
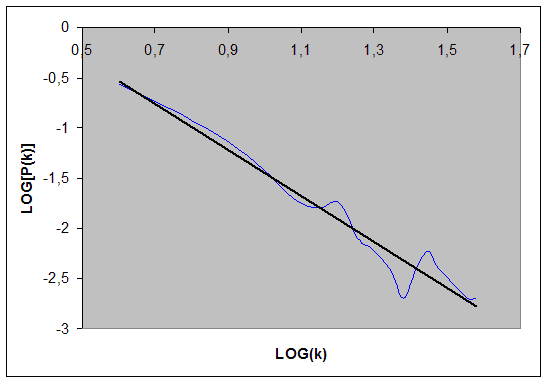
Per osservare meglio il decadimento della curva in fig. 7 prendiamo in esame solo l’intervallo in cui questa è decrescente e utilizziamo le coordinate logaritmiche: Figura 8 – curva precedente in coordinate logaritmiche con linea di tendenza.
Come si vede, ![]()
![]()


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In coordinate logaritmiche diventa: Figura 10 – curva precedente in coordinate logaritmiche con linea di tendenza.
Anche qui ritroviamo l’andamento tipico della power law con un coefficiente circa pari a ![]()
7. Problemi aperti e prospettive
L’analisi condotta si è concentrata sulla WM, ma è del tutto ragionevole che- anche su scale temporali diverse, meno “frenetiche” per via dei pesi-, anche la LTM dovrebbe assumere la conformazione di un grafo scale-free. Le modalità di organizzazione della LTM non permettono però la definizione di un semplice modello matematico necessario per poter fare previsioni sulla sua evoluzione. Lungi dall’essere un limite, questo è un indizio significativo di carattere sistemico.La LTM rappresenta il “deposito” di risorse cognitive che entra in gioco e si accresce durante le sessioni di lavoro della WM. Poiché queste sono guidate dall’utente secondo finalità che possono variare di volta in volta, è chiaro che la LTM riflette in qualche modo la varietà di esperienze cognitive dell’utente, e si organizza in modo largamente impredicibile.Consideriamo le ragioni essenziali per comprendere questa differenza tra WM e LTM.
Nei modelli di rete scale-free presenti in letteratura ad ogni passo temporale vengono aggiunti alla rete M nuovi nodi con M definito a priori. Questi stabiliscono M collegamenti con M vecchie unità della rete.
Nel caso del nostro sistema, dopo l’analisi di ogni nuovo documento vengono aggiornati i collegamenti relativi ad un numero imprecisato di nodi della LTM, sulla base del contenuto della WM. Tale numero varia da documento a documento in quanto rappresenta il numero di parole contenute nel documento che non vengono filtrate dalla stoplist.
Abbiamo notato inoltre come un’ importante differenza con i modelli di rete scale-free presentati in letteratura risiede nella funzione di fitness utilizzata, che non dipende da un singolo nodo, ma dalla coppia di nodi considerata. Del resto nel caso delle reti associative è lecito aspettarsi che la funzione di fitness associata ad ogni parola dipenda anche da quella con cui si vuole stabilire il collegamento. Ad esempio la parola home dovrebbe presentare un punteggio di fitness più elevato nei confronti di door rispetto ad altre parole come person o industry. Inoltre questo garantisce un monitoraggio più efficiente degli hub. Naturalmente è possibile introdurre funzioni di fitness ancora più complicate, relative a cluster di nodi. Questa scelta si riflette però in una scala temporale più lenta per la formazione di una chiara struttura scale-free nella LTM.
Per migliorare l’efficienza del sistema è possibile introdurre varie forme di feedback esterno, in modo da valutare le performance del sistema nell’espletazione di compiti particolari, come la ricerca od il filtraggio dei documenti in rete. L’accettazione ed il rifiuto dei documenti selezionati dal sistema da parte degli utenti potrebbe riflettersi nella modalità di aggiornamento della LTM. Nel primo caso il contenuto della WM servirebbe per rafforzare i collegamenti della LTM già esistenti e per crearne di nuovi secondo le modalità già esposte, nel secondo caso servirebbe invece per indebolire alcuni collegamenti della LTM.
La doppia scala temporale fa sì che la formazione della rete rappresentante la WM non influenza velocemente l’informazione relativa ai pesi dei collegamenti presenti nella LTM. Anche se questi vanno considerati durante la procedura della diffusione dell’attivazione che porta all’ampliamento del contenuto del buffer, l’informazione contenuta nella LTM condiziona lentamente il valore della funzione di fitness utilizzato per il calcolo della probabilità della formazione di un collegamento nella WM. Anche questo aspetto ha un significato molto chiaro in termini cognitivi: l’esperienza accumulata su lunghe scale temporale e su ampi domini si riflette poi anche su attività più concentrate e su scale temporali più brevi.
Alcune simulazioni recenti hanno fornito forti indicazioni in favore di una struttura scale-free della LTM, sebbene con caratteristiche piuttosto diverse da quelle della WM, in accordo con quanto abbiamo detto. In altre parole, quando il dominio semantico è fissato il grafo della LTM converge rapidamente verso uno stato con un alto tasso di clustering. Una nuova seduta di information retrieval su un nuovo testo, “rompe” questa coerenza nella LTM, e l’intero sistema può essere considerato come un amplificatore di informazione in cui emergono nuove strutture cognitive, e nuovi hub.Questo equivale ad un’espansione del dominio semantico a “largo raggio” del sistema utente-rete.
Infine, l’associazione di un’età ai collegamenti della LTM potrebbe garantire una maggiore plasticità a tale forma di rappresentazione.Ad esempio, la funzione di fitness potrebbe considerare un “invecchiamento” (aging) dei collegamenti con un tasso di decadimento per le connessioni meno attivate nel corso di un fissato intervallo di tempo.
8. Conclusioni
E’ stato presentato un nuovo sistema per l’acquisizione dinamica della conoscenza basato sul concetto di Long Term Working Memory sviluppato da Kintsch ed Ericsson.
Tale sistema porta alla formazione e all’aggiornamento di una rete associativa (Long Term Memory), la cui struttura varia dinamicamente nel tempo sulla base del contenuto testuale dei documenti analizzati. Durante l’analisi di ogni nuovo documento la LTM può essere interrogata attraverso una semplice procedura di diffusione dell’attivazione dei collegamenti. Questo permette una precisa individuazione del contesto del documento analizzato.
I test hanno mostrato sia per la WM che per la LTM una tipica struttura a grafo scale-free, cosa che indica in queste reti associative un processo di auto-organizzazione con caratteristiche emergenti che corrispondono ad una modificazione del dominio cognitivo correlato all’attività dell’utente E’ sbagliato comunque parlare di una “rete intelligente” per motivi epistemologici. Quello che possiamo dire è che questi nuovi modelli di interfacciamento uomo-macchina permettono un ampliamento del dominio semantico del sistema agente umano-rete inteso sistemicamente come un tutto. Se la “macchina intelligente” è un sogno lontano, e forse non propriamente utile, sicuramente è nelle possibilità della ricerca attuale condividere con la rete parte delle nostre strategie cognitive.
Leggi anche:
1° Saggio
Gli autori:
Ignazio Licata è un fisico teorico. Si occupa di sistemi complessi e processi cognitivi. E’ direttore scientifico dell’ISEM, Institute for Scientific Methodology per gli Studi Interdisciplinari, Palermo.
Luigi Lella è laureato in ingegneria informatica presso il DEIT dell’Università Politecnica delle Marche, dove attualmente svolge il dottorato di ricerca. Si occupa di parsing semantico nell’analisi dei testi e di reti neurali auto-organizzanti.
William Giordano è laureato in ingegneria elettronica presso il DEIT dell’Università Politecnica delle Marche. Si occupa di analisi dei dati in simulazioni di reti evolutive.
Bibliografia
1. W.Kintsch, Comprehension. A Paradigm for Cognition, CambridgeUniversity Press, 1998.
2. J.A. Fodor, La mente modulare.Saggio di psicologia delle facoltà, Ed. Il Mulino, Bologna,1999.
3.D.E.Meyer & R.W.Schvaneveldt, Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations, in Journal of Experimental Psychology,90,pp.227-234,1971.
4. A.M. Collins & M.R. Quillian, Retrieval from semantic memory, in Journal of Verbal Learning and Verbal Behaviour, 8, pp.240-247, 1969.
5. M. Minsky, La società della mente,Ed.Adelphi, Milano, 1989.
6. R.C. Schank & R.P. Abelson, Scripts, plans,goals, and understanding, Hillsdale ,NJ, Erlbaum, 1977.
7. W.Kintsch, The Representation of Knowledge in Minds and Machines, in Int. Jour. of Psychology, 33(6), pp.411-420, 1998.
8. W.Kintsch, V.L. Patel, K.A.Ericsson, The role of long-term working memory in text comprehension, in Psychologia, 42, pp.186-198, 1999.
9.T.A. van Dijk, W. Kintsch, Strategies of discourse comprehension, Academic Press, NY, 1983.
10. J.L. McClelland & D.E. Rumelhart, Parallel distributed processing, Cambridge, MA: MIT Press, 1986.
11. G. A. Miller. Five papers on WordNet. Cognitive Science Laboratory Report 43, 1993.
12. L.Lella, Analisi della Semantica nel Web attraverso Reti Neurali Auto Organizzanti, tesi di laurea in Ingegneria Elettronica, Università Politecnica delle Marche, aa.2001-2002.
13. I. Licata, Mente & Computazione, in Systema Naturae 5(2003), ripubblicato in Quaderni di Filosofia Naturale, Ed. Andromeda, Bologna, 2004.
14. R.Albert & A.L.Barabasi, Statistical Mechanics of Complex Networks,in Rev. Mod. Phys., no.74, pp.47-97, 2001.
15. G. Bianconi & A.L. Barabasi, Bose-Einstein Condensation in Complex Networks, in Phys. Rev. Lett. Vol.86,n 24, 2001.
16. M.Steyvers & J.Tenenbaum, The Large-Scale structure of Semantic Networks, working draft presentato a Cognitive Science, 2001.
17. Reuters Corpus, Vol.1,English language,1996-08-20 to 1997-08-19, http://about.reuters.com/researchandstandards/corpus .
18. S.N. Dorogovtsev, J.F.F. Mendes, Evolution of networks, arXiv: cond-mat/0106144, presentato a Adv. Phys., 2001.
19. S.N. Dorogovtsev, J.F.F. Mendes, Evolution of reference networks with aging, arXiv: cond-mat/0001419, 2000.
20. Romualdo Pastor-Satorras & Alessandro Vespignani, Evolution and Structure of the Internet. A Statistical Physics Approach, CambridgeUniv. Press, 2004.